Least squares is a widely used class of convex optimization that can be applied
to solve a variety of problems, for instance: in statistics for curve fitting,
in machine learning to compute support vector machines , in robotics to solve
inverse kinematics , etc. They are
related to quadratic programming (QP), having a slightly more
intuitive objective function, and the first step beyond linear programming (LP)
in convex optimization.
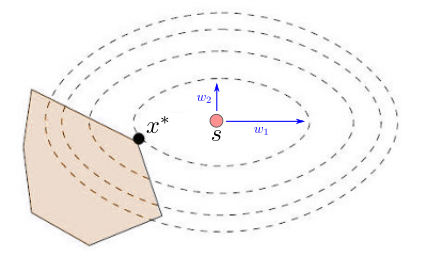
Graphical interpretation
Let us illustrate the intuition behind this in 2D:
In the figure above, the level sets of the weighted norm are represented by
ellipses centered on the target s \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
s s s \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
s s x ∗ \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
x^* x ∗
In this example, the matrix R \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
R R i.e. x \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
x x s \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
s s W = d i a g ( w 1 , w 2 ) \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
W = \mathrm{diag}(w_1, w_2) W = diag ( w 1 , w 2 )
∥ x − s ∥ W 2 = w 1 ( x 1 − s 1 ) 2 + w 2 ( x 2 − s 2 ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
\| x - s \|^2_W = w_1 (x_1 - s_1)^2 + w_2 (x_2 - s_2)^2 ∥ x − s ∥ W 2 = w 1 ( x 1 − s 1 ) 2 + w 2 ( x 2 − s 2 ) 2 The weights w 1 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
w_1 w 1 w 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
w_2 w 2 ( x 1 − s 1 ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
(x_1 - s_1)^2 ( x 1 − s 1 ) 2 ( x 2 − s 2 ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
(x_2 - s_2)^2 ( x 2 − s 2 ) 2 w 1 / w 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
w_1 / w_2 w 1 / w 2 ( x 2 − s 2 ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
(x_2 -
s_2)^2 ( x 2 − s 2 ) 2 ( x 1 − s 1 ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
(x_1 - s_1)^2 ( x 1 − s 1 ) 2
Question : in the figure above, what is the largest weight, w 1 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
w_1 w 1 w 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
w_2 w 2
Python example
Suppose we have access to a solve_ls function that solves least squares
problems in standard form. For instance, the qpsolvers module provides one directly if you
are using Python. Let us then see how to solve the following LS:
m i n i m i z e x 1 , x 2 , x 3 ∥ [ 1 2 0 − 8 3 2 0 1 1 ] [ x 1 x 2 x 3 ] − [ 3 2 3 ] ∥ 2 s u b j e c t t o [ 1 2 1 2 0 1 − 1 2 − 1 ] [ x 1 x 2 x 3 ] ≤ [ 3 2 − 2 ] \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
\begin{align*}
\underset{{x_1, x_2, x_3}}{\mathrm{minimize}} \quad & \left\| \left[\begin{array}{ccc}
1 & 2 & 0 \\
-8 & 3 & 2 \\
0 & 1 & 1 \end{array}\right] \left[\begin{array}{c} x_1 \\ x_2 \\
x_3\end{array}\right] - \left[\begin{array}{c} 3 \\ 2 \\
3\end{array}\right] \right\|^2 \\
\mathrm{subject\ to} \quad & \left[\begin{array}{ccc}
1 & 2 & 1 \\
2 & 0 & 1 \\
-1 & 2 & -1 \end{array}\right] \left[\begin{array}{c} x_1 \\ x_2 \\
x_3\end{array}\right] \leq \left[\begin{array}{c}
3 \\ 2 \\ -2 \end{array} \right]
\end{align*} x 1 , x 2 , x 3 minimize subject to 1 − 8 0 2 3 1 0 2 1 x 1 x 2 x 3 − 3 2 3 2 1 2 − 1 2 0 2 1 1 − 1 x 1 x 2 x 3 ≤ 3 2 − 2 First, we write our LS matrices in proper format:
R = array ([[ 1. , 2. , 0. ], [ - 8. , 3. , 2. ], [ 0. , 1. , 1. ]])
s = array ([ 3. , 2. , 3. ])
G = array ([[ 1. , 2. , 1. ], [ 2. , 0. , 1. ], [ - 1. , 2. , - 1. ]])
h = array ([ 3. , 2. , - 2. ])
W = eye ( 3 )
Finally, we compute the solution using the solve_ls function:
In [ 1 ]: solve_ls ( R , s , G , h , W = W )
Out [ 1 ]: array ([ 0.12997347 , - 0.06498674 , 1.74005305 ])
Problem shaping
In fields such as optimal control, a lot of human work lies in solving the
inverse problem: think of a desired behavior, formulate it as a numerical
optimization problem, run the system, realize that the optimal solution to the
problem is not what one wanted in the first place, update the problem
accordingly, iterate. This process challenges us to get better at problem
shaping: how to modify the problem to steer the behavior of its optimum towards
what we want?
Diagonal weight matrix
The first trick in the book is to use a diagonal weight matrix, and play with
its weight to adjust the relative importance of one sub-objective, that is, one
term ( R i x − s i ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
(R_i x - s_i)^2 ( R i x − s i ) 2
W = d i a g ( w 1 , … , w k ) = [ w 1 0 ⋯ 0 0 w 2 ⋱ ⋮ ⋮ ⋱ ⋱ 0 0 ⋯ 0 w k ] \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
W = \mathrm{diag}(w_1, \dots, w_k) =
\begin{bmatrix}
w_1 & 0 & \cdots & 0 \\
0 & w_2 & \ddots & \vdots \\
\vdots & \ddots & \ddots & 0 \\
0 & \cdots & 0 & w_k
\end{bmatrix} W = diag ( w 1 , … , w k ) = w 1 0 ⋮ 0 0 w 2 ⋱ ⋯ ⋯ ⋱ ⋱ 0 0 ⋮ 0 w k This weighting produces the objective function:
∥ R x − s ∥ W 2 = ∑ i = 1 k w i ( R i x − s i ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
\| R x - s \|^2_W = \sum_{i=1}^k w_i (R_i x - s_i)^2 ∥ R x − s ∥ W 2 = i = 1 ∑ k w i ( R i x − s i ) 2 If the behavior of the solution is too poor on one sub-objective i \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
i i k \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
k k ( R i x ∗ − s i ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
(R_i x^* - s_i)^2 ( R i x ∗ − s i ) 2 x ∗ \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
x^* x ∗ w i \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
w_i w i j ≠ i \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
j \neq i j = i
To explain this informally, let us get rid of the scale invariance of these
weights. The facts that all weights are positive makes the expression ∥ R x − s ∥ W 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
\|
R x - s \|^2_W ∥ R x − s ∥ W 2 conical combination of squared residuals
( R i x − s i ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
(R_i x - s_i)^2 ( R i x − s i ) 2 convex combination :
∑ i = 1 k w i = 1 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
\sum_{i=1}^k w_i = 1 i = 1 ∑ k w i = 1 Given any weighted LS problem, we can always renormalize the weights (dividing
them by their collective sum) to get to an equivalent problem where weights
form a convex combination. We can then focus without loss of generality on
problems whose weights form a convex combination.
Intuitively, increasing a weight w i \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
w_i w i ( R i x ∗ − s i ) 2 \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
(R_i x^* - s_i)^2 ( R i x ∗ − s i ) 2 w i \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
w_i w i w j \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
w_j w j ( j ≠ i ) \def\bfA{\boldsymbol{A}}
\def\bfB{\boldsymbol{B}}
\def\bfC{\boldsymbol{C}}
\def\bfD{\boldsymbol{D}}
\def\bfE{\boldsymbol{E}}
\def\bfF{\boldsymbol{F}}
\def\bfG{\boldsymbol{G}}
\def\bfH{\boldsymbol{H}}
\def\bfI{\boldsymbol{I}}
\def\bfJ{\boldsymbol{J}}
\def\bfK{\boldsymbol{K}}
\def\bfL{\boldsymbol{L}}
\def\bfM{\boldsymbol{M}}
\def\bfN{\boldsymbol{N}}
\def\bfO{\boldsymbol{O}}
\def\bfP{\boldsymbol{P}}
\def\bfQ{\boldsymbol{Q}}
\def\bfR{\boldsymbol{R}}
\def\bfS{\boldsymbol{S}}
\def\bfT{\boldsymbol{T}}
\def\bfU{\boldsymbol{U}}
\def\bfV{\boldsymbol{V}}
\def\bfW{\boldsymbol{W}}
\def\bfX{\boldsymbol{X}}
\def\bfY{\boldsymbol{Y}}
\def\bfZ{\boldsymbol{Z}}
\def\bfalpha{\boldsymbol{\alpha}}
\def\bfa{\boldsymbol{a}}
\def\bfbeta{\boldsymbol{\beta}}
\def\bfb{\boldsymbol{b}}
\def\bfcd{\dot{\bfc}}
\def\bfchi{\boldsymbol{\chi}}
\def\bfc{\boldsymbol{c}}
\def\bfd{\boldsymbol{d}}
\def\bfe{\boldsymbol{e}}
\def\bff{\boldsymbol{f}}
\def\bfgamma{\boldsymbol{\gamma}}
\def\bfg{\boldsymbol{g}}
\def\bfh{\boldsymbol{h}}
\def\bfi{\boldsymbol{i}}
\def\bfj{\boldsymbol{j}}
\def\bfk{\boldsymbol{k}}
\def\bflambda{\boldsymbol{\lambda}}
\def\bfl{\boldsymbol{l}}
\def\bfm{\boldsymbol{m}}
\def\bfn{\boldsymbol{n}}
\def\bfomega{\boldsymbol{\omega}}
\def\bfone{\boldsymbol{1}}
\def\bfo{\boldsymbol{o}}
\def\bfpdd{\ddot{\bfp}}
\def\bfpd{\dot{\bfp}}
\def\bfphi{\boldsymbol{\phi}}
\def\bfp{\boldsymbol{p}}
\def\bfq{\boldsymbol{q}}
\def\bfr{\boldsymbol{r}}
\def\bfsigma{\boldsymbol{\sigma}}
\def\bfs{\boldsymbol{s}}
\def\bftau{\boldsymbol{\tau}}
\def\bftheta{\boldsymbol{\theta}}
\def\bft{\boldsymbol{t}}
\def\bfu{\boldsymbol{u}}
\def\bfv{\boldsymbol{v}}
\def\bfw{\boldsymbol{w}}
\def\bfxi{\boldsymbol{\xi}}
\def\bfx{\boldsymbol{x}}
\def\bfy{\boldsymbol{y}}
\def\bfzero{\boldsymbol{0}}
\def\bfz{\boldsymbol{z}}
\def\defeq{\stackrel{\mathrm{def}}{=}}
\def\p{\boldsymbol{p}}
\def\qdd{\ddot{\bfq}}
\def\qd{\dot{\bfq}}
\def\q{\boldsymbol{q}}
\def\xd{\dot{x}}
\def\yd{\dot{y}}
\def\zd{\dot{z}}
(j \neq i) ( j = i )
To go further
Least squares is covered in Chapter 10 of Nocedal and Wright's Numerical
Optimization , as well as in
Section 1.2 of Boyd and Vandenberghe's Convex Optimization . It is closely
related to quadratic programming, and we can cast LS problems to QP in
order to use readily available QP solvers.
Using relative weights in a linearly constrained optimization is a particular
instance of lexicographic optimization
with two levels of priority. Thinking in terms of levels of priority sheds a
new light on problem shaping. For instance, when one weight gets predominant
over the others, our LS problem becomes (increasingly difficult to solve and)
closer to a three-level optimization. In that case, we can get better
performance by using a proper lexicographic solver. See Section 2 of Geometric
and numerical aspects of redundancy for a concrete discussion on
this.
Discussion
Feel free to post a comment by e-mail using the form below. Your e-mail address will not be disclosed.